I have been a long-term Windows user. I started developing an application under Windows 1 (a disaster due to memory leaks in the OS), I developed device drivers under Windows 3.1. I have 4 computers at home quite happily running Windows 10, and with very little frustration.
Why then should I want to migrate to Linux? There are multiple reasons. Perhaps the most important is that Microsoft has branded most of my hardware unfit to run its next revision of Windows; at some point Windows 10 will cease to be supported and vendors of the various Apps I depend on will stop supporting it. The second reason (and perhaps an equal first) is that I like to tinker, and Linux has plenty of scope for tinkering. Thirdly, I am familiar with running Linux, which I use on my home server. Finally, I wanted to use ZFS to provide management and protection of my filesystem.
But can I drop Windows entirely? Unfortunately not. A couple of the apps I depend on run only in Windows. These are VideoPsalm (which is used to present in Church) and Microsoft Access (which I use to maintain multiple databases, e.g., for a publication I edit).
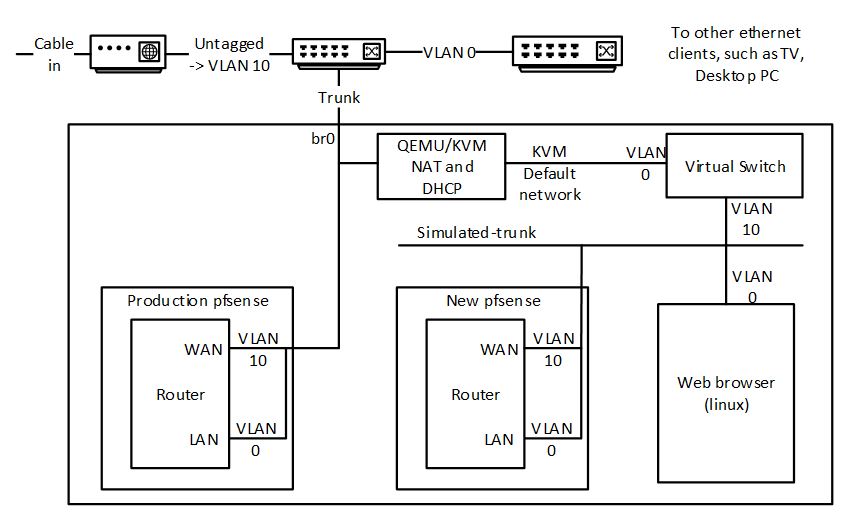
I would really like to have moved my existing Windows 10 installation into the virtual domain. I never did find a way to do this. I tried virtualizing the nvme PCI hardware in qemu-kvm. I moved my installation to an SSD (where it still booted) and then virtualized this as a raw block device. The boot up in the virtual machine (VM) gave an error on a fetchingly attractive light blue background (gone are the bad old days of dark blue). Booting the Windows 10 installation image and attempted to repair the installation failed. I could boot it in safe mode, but not in normal mode. Eventually I gave up and bought a one-time install license for Windows 10, and for Microsoft Office, which I was able to install in a fresh VM. There I was able to continue to use VideoPsalm and Microsoft Access (Office).
Here is a list of observations from this work:
- I selected Zorin 16 Core (based on Ubuntu 20.04) as my OS. It has good reviews. The Core version is free, but the existence of paid versions means the features in Core get professional attention. It’s based on Ubuntu 20.04 LTS, which is also well maintaned.
- I initially installed Zorin 16 to a SSD using ext4 as the filesystem, then I moved the installation to my nvme using the zfs filesystem (separate boot and root pools). I kind-of followed some of the ideas in the Ubuntu ZSYS project, having separate datasets for the root, and each user. However, I did not use the OS option to install on zfs because I have found zsys to be buggy, and in the past it failed me when I needed it most.
- Ubuntu 20.04 domain name resolution is a right pain too if you have a local DNS server. I disabled Network Manager and used netplan (rendered by networkd) to define a bridge (needed by the virtual machines) with static IP and DNS settings. If I relied on the values supplied by my DHCP server, the OS would occasionally reset itself so that it resolved only external names, and sometimes didn’t work at all. I never did find out why.
- Linux apps, in general, do not talk to data on the network directly. I mounted my network resources using nfs in the fstab.
- Printing proved to be a right royal pain in the posterior. I spent a day messing about with different printer drivers and trying to coerce otherwise functional programs to behave rationally. I ended up insalling Gutenprint drivers for my Canon mx925 printer, and installing a printer using the same connection for each combination of job options (page size, borderless printing, paper type) that I wanted, because applications generally don’t seem to want to remember prior combinations of print options.
- Sound. Managing sound devices is also a pain in the derriere. Ubuntu 20.04 / Zorin uses Pulse Audio. Some applications work seamlessly (e.g. Zoom). Others support ALSA device selection, or the Pulse Audio default device, such as Audacity and Skype. Evenually I learned to disable a device in Pulse Audio in order to allow Audacity to access it via ALSA, reserving headphones for editing, and my main speakers for everything else. But, Pulse has the annoying habits of randomly changing the “fallback”=default output device, for no reason that I could find. I ended up keeping the Pulse volume control open to manage which device audio should come out of. I also had to edit the pulse config files to specify initial default source and sink, because it appeared to have no memory from boot to boot of device selection.
- I had to be sensitive to the source of a program: OS-supplied, supplied by a PPA (i.e., an unofficial release for the OS), Snap, Flatpack or AppImage. Snap and Flatpack applications are isolated from much of the machine – for example, limiting the user’s home directory subdirectories that are visible, and making the printer unavailable. Also start-up time for Snap, Flatpack and AppImage applications may be slow. Opera installed from Snap had a 10-second start-up time. This is not acceptable, IMHO.
And comments on specific applications:
- Thunderbird is my go-to email, calendar and contacts app. Works seamlessly in Linux.
- Audacity is used for my audio narration. I encountered a number of issues. The latest AppImage (3.1.2) has one feature I use (Noise Reduction) slowed down a factor of seval, and when installed as a Flatpack, it slows down a factor of several more. I had to install an old version (3.0.2) from a PPA, which restored the speed.
- My image library is managed using Faststone on Windows. I evaluated a number of alternatives on Linux. I wanted to use Shotwell, but found it too unstable – crashing for some drag-and-drop operations. I settled on digiKam, which is way more powerful than I need. However, printing images in digiKam has issues. Using the print tool from the LightTable results in weird cropping aspect ratios, i.e., the first print is OK, but subsequent prints are stretched or squashed. I resorted to printing one-at-a-time using GIMP.
- Google drive. I was unwilling to pay for a linux replacement. I evaluated some of the free alternatives with no success. So I reduced by dependence on it, and used the gnome ability to see it as a directory under nautilus to drag and drop files into it, rather than accessing files in the Google drive direct from applications.
- Desktop search. Part of my self-employed work requires me to research in a large corpus of Microsoft Office files. I uses Lookeen (paid) on Windows. After some evaluation, I settled on Recoll under Linux. I did have to work around a system crash that occurred when Recoll indexed my 40GB corpus directly mounted on nfs. I synchronised the files to a local directory (using ownCloud) and Recoll indexed that without issue.
- Voip client. I was using MicroSIP on Windows. I evaluated the usual suspects on Linux (Linphone, Twinkle). Eventually I was forced to drop the open source choices due to limitations or bugs and go with the free version of Zoiper, which perfectly meets my needs.
- Brower. My Windows preference is Opera, although there are some websites that don’t like it. Under Linux the limitations of Opera are more evident. I moved to Firefox, which also has support for hardware video acceleration, an added plus.
- What’s App: there is no native App, but web.whatsapp.com works well enough in a browser.
- Applications which work seamlessly in both environments:
- RSS reader: QuiteRSS
- Video editor: Shotcut
- Teamviewer
- Ultimaker Cura
- FreeCad
- Zoom
- Calibre
- Heidi SQL
- Inkscape